Chapter 3 Basic Data Cleaning with OpenRefine
Let’s dive into our data with some basic exploration and cleaning.
3.1 Splitting Columns
Sometimes you have more than one data point in a column and need to separate it out so you can analyze it separately (similar to the Text to columns operations in Excel)
- Let’s split
Serving Sizeinto two columns – one for the amount and one for the unit- Using the drop-down menu select
Edit Column>Split into several Columns- by separator (change to a blank space) >split into 2 columns at most> uncheckremove this column
- Using the drop-down menu select
- We now have two new columns – one called
Serving Size 1and one calledServing Size 2let’s rename themServing AmountandServing Unitby clicking onEdit column>Rename this column - Challenge: Use the
splitfeature to divide theDate Entered into DSLD columninto two columns, one for date and one for time. Can we conclude anything about the times?
3.2 Undo/Redo
When we make a mistake in OpenRefine, we use Undo/Redo rather than a back button.
- Let’s say we didn’t actually want to split
Date Entered into DSLDinto two columns. Click onUndo/Redoand select the action before the one we just did. Our split has now disappeared.
3.3 Faceting Data
Faceting is one of the best parts of OpenRefine and can be used in a variety of ways including to get a snapshot of unique variables and to spot potential errors in your data.
Let’s facet to get a snapshot of our data:
- We can scroll down to see if our splits have worked correctly but it is always smart to double check with a facet. Let’s get a snapshot of our new
Serving Unitcolumn by selectingFacet>Text facet - On the left we can now see a list of all the different values in this column in alphabetical order or by count. There should be 433 choices. If we click on any of the options we will filter to just those rows.
- Some of the
Serving Unitslook a little odd, but they were actually provided that way by the manufacturer so we will leave them for now.
- Some of the
- Challenge: What Brand makes a supplement that comes in the form of “Gummy Dolphin(s)”?
- Challenge: Use the
Facetfeature on theServing Amountcolumn. How many unique variables are there? What is the most frequent serving amount?
Now let’s use faceting to find some potential mistakes:
- Now let’s try faceting the
LanguaL-Product Typecolumn. It looks like we have 14 choices but some of these look a little odd. For example, it looks like we have 25 records forAmino acid/protein [A1305and 2325 records forAmino acid/protein [A1305]. In this case we know that those 25 records should say[A1305].To fix this, we can clickEditnext to those records, update the records, and selectApply. No we have 13 choices - It looks like there are a couple more spelling mistakes in this column, we could fix them manually as we did above, but let’s hold off and use the clustering feature later.
- Challenge: Facet the
Brands Namescolumn, how many options are there? Do you see any potential mistakes? - Challenge: Explore the other kinds of facets, do any of these seem useful to you?
3.4 Trimming Whitespace and Changing to Titlecase
- Some of the names in our
Brand Namecolumn look very similar. Before we spend a lot of time trying to manually clean or cluster all 1778 of them let’s try two easy cleaning steps. - First, let’s change everything to titlecase by selecting
Edit cells>Common transforms>To titlecase– now we have 1693 options. - We might also want to trim any whitespace at the beginning or end of the row on the
Brand Namecolumn by selectingEdit cells>Common transforms>Trim leading and trailing whitespace. Note that on version 3.4 and above this will not make a difference as whitespace is automatically removed. - Note that you can now apply these actions to all columns at once using
All>Edit all Columns
3.5 Clustering Data
Now let’s clean up the rest of our Brand Name column using Clustering! Clustering is one of the most powerful features in OpenRefine! Clustering is a tool for grouping names that are similar so that we can bulk edit them – it works on the syntactic level (spelling) not semantic (meaning)
- In the
Facetwindow for our column, let’s hitClusterin the upper right-hand corner - OpenRefine uses two main algorithms for clustering the data:
key collision: generates a key from a value based on common transformations (what is the core value when you remove whitespace/capitalization/punctuation)nearest neighbor: each unique value is compared to every other unique value using a distance function
- Fortunately, we don’t really need to understand the algorithms because it is easy to try them all!
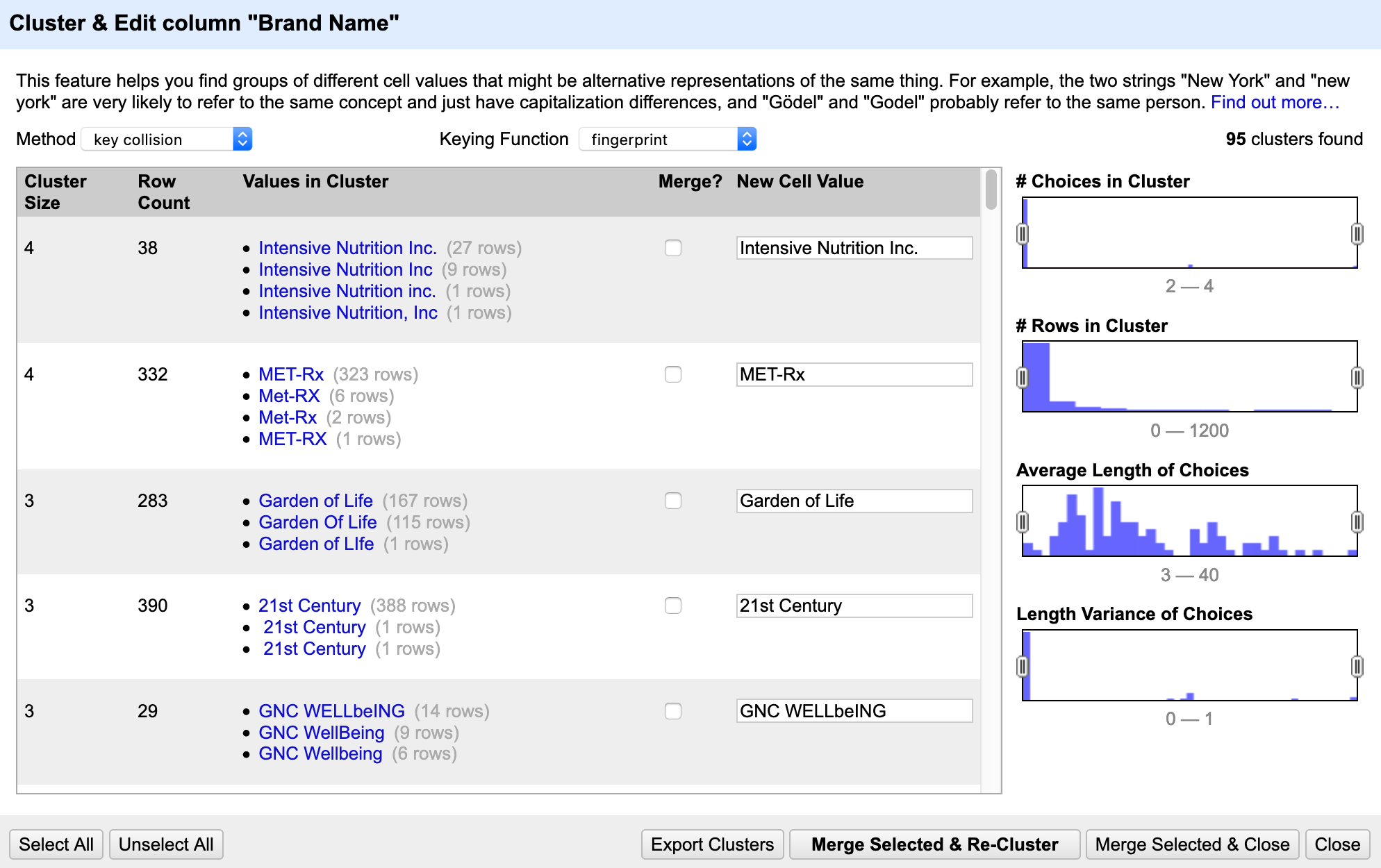
- In the clustering box we can see:
Cluster Size: how many different options in that clusterRow Count: how many rows will be changedValues in Cluster: possible optionsMerge?: check box if you wish to merge those cellsNew cell value: what the cell should say
- Start with the
Key CollisionMethod and work your way through theKeying function– there should be many options to cluster. If they all look good you can useSelect allin the bottom left (note that you might need to decrease the size of your window to see this)- If the selected replacement looks correct we can check the
Mergebox and then clickMerge selected and re-clusterat the bottom - As you work through the remaining algorithms you might see that some work better than others. Take a look at all the options but only cluster using the
Key Collision–fingerprint,ngram fingerprintandNearest Neighbor–levenshteinYou should have approximately 1625 choices now (but don’t worry if you don’t have the same number)
- If the selected replacement looks correct we can check the
- Challenge: Which methods and keying functions do not seem like they will work for the Brand Name column?
- Challenge:
FacetandClustertheLanguaL-Product Typecolumn. How many unique variables do you end up with?
3.6 Sorting
- Right now the data is sorted by
Brand Namefirst, what if we wanted to sort byDSLD ID? - Under
DSLD IDselectSortand we want to sort bynumbers. Note that we can position errors and blanks at the beginning to help us spot them if we want. HitOkwhen you are happy with your sort.- You can edit your sort by selecting
Sortagain under the specific column. You can also selectSort>ReverseorRemove sortto undo (since it is not listed in theUndo/redocolumn). - Note that this didn’t add any steps to the
Undo/Redo- the sort is not permanent - If we wanted it to be permanent we would select
Sortin the top middle >Reorder rows permanently
- You can edit your sort by selecting
- We can sort by multiple things, just sort each row in the order you want them sorted (view the order in the sort menu) ex: sort
DSLD IDthenBrand Name